Regresja logistyczna z wykorzystaniem biblioteki SKLEARN
Przykład 1:
Regresja logistyczna do predykcji udziału w ultramaratonie.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.preprocessing import OrdinalEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
# Dane wejściowe
d = {
'miles_per_week': [37,39,46,51,88,17,18,20,21,22,23,24,25,27,28,29,30,31,32,33,34,38,40,56,72,67,90,92,62,77,88,99,66,18,46,99,75,84,12,65,45,38,73,46,95,48,32,65,15,48,65,45,51,25,35,53,64,48,9,77],
'completed_50m_ultra': ['no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','no','yes','yes','yes','yes','yes','yes','yes','yes','yes','yes','no','no','yes','yes','yes','no','yes','no','no','yes','no','yes','yes','no','no','no','yes','yes','yes','no','no','no','yes','yes','no','no','yes']
}
df = pd.DataFrame(data=d)
# Zamiana 'no'/'yes' na 0/1
enc = OrdinalEncoder(categories=[['no', 'yes']])
df['completed_50m_ultra'] = enc.fit_transform(df[['completed_50m_ultra']])
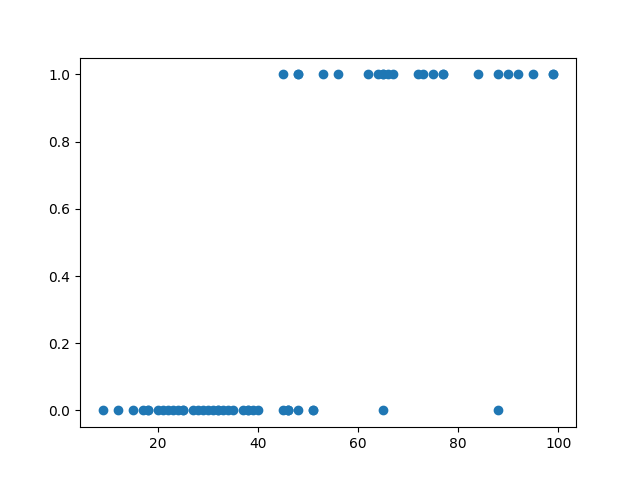
# Wykres rozrzutu (scatter plot)
plt.figure(figsize=(8,5))
plt.scatter(df['miles_per_week'], df['completed_50m_ultra'], color='blue', label='Dane obserwowane')
plt.xlabel("Liczba mil tygodniowo")
plt.ylabel("Ukończenie ultramaratonu (0 = nie, 1 = tak)")
plt.title("Dane treningowe: liczba mil vs. sukces")
plt.grid(True)
# Trening modelu regresji logistycznej
X = df[['miles_per_week']]
y = df['completed_50m_ultra']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
# Wykres krzywej regresji logistycznej
x_range = np.linspace(df['miles_per_week'].min(), df['miles_per_week'].max(), 300).reshape(-1, 1)
y_proba = model.predict_proba(x_range)[:, 1]
plt.plot(x_range, y_proba, color='red', linewidth=2, label='Krzywa regresji logistycznej')
plt.legend()
plt.show()
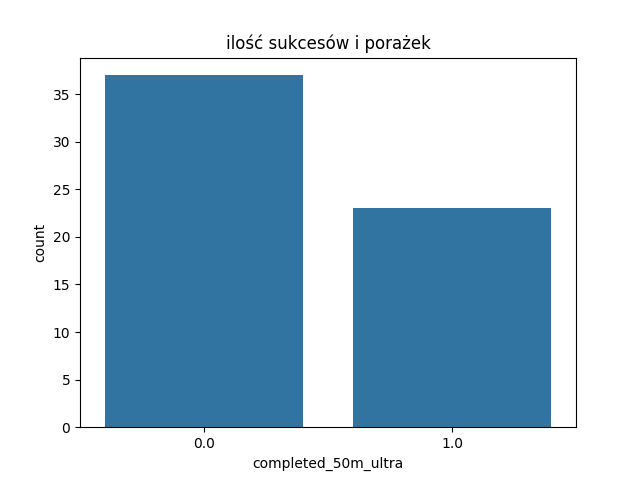
# Wizualizacja z seaborn – liczba sukcesów i porażek
sns.countplot(x='completed_50m_ultra', data=df)
plt.title("Liczba osób, które ukończyły / nie ukończyły ultra")
plt.xticks([0, 1], ['Nie', 'Tak'])
plt.show()
# Ocena modelu
y_pred = model.predict(X_test)
print("Dokładność modelu:", model.score(X_test, y_test))
print("Macierz konfuzji:\n", confusion_matrix(y_test, y_pred))
print("Raport klasyfikacji:\n", classification_report(y_test, y_pred))
# Przykładowa predykcja
miles = 77
predicted = model.predict([[miles]])[0]
prob = model.predict_proba([[miles]])[0][1]
print(f"Dla {miles} mil/tyg. model przewiduje ukończenie ultramaratonu: {int(predicted)} (prawdopodobieństwo: {prob:.2f})")
Wykres populacji danych.
Wykres kolumnowy sukcesów i porażek.
 Przykład 2:
Przykład 2:
Regresja logistyczna do predykcji śmiertelności pasażerów tytanika.
from pydataset import data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
titanic=data('titanic')
print(titanic.sample(5))
titanic=pd.get_dummies(titanic, drop_first=True)
print(titanic.sample(5))
X_train, X_test, y_train, y_test=train_test_split(titanic.drop('survived_yes',axis=1),titanic['survived_yes'])
LogReg=LogisticRegression(solver='lbfgs')
LogReg.fit(X_train, y_train)
print("Czy dziecko, płci żeńskiej w klasie 1 przeżyje? ",LogReg.predict(np.array([[0,0,1,1]]))[0]) # class 1 child girl survived?
print("Czy dorosły mężczyzna w klasie 3 przeżyje ?",LogReg.predict(np.array([[0,1,0,0]]))[0]) # class 3 adult male Survived?
# Analiza trafności modelu
print('Wynik poprawności przeiwdywania modelu ',LogReg.score(X_test,y_test))