Rozpoznawanie liczb pisanych odręcznie z pomocą algorytmu random forest
import pandas as pd
from sklearn.datasets import load_digits
digits=load_digits()
dir(digits)
import matplotlib.pyplot as plt
plt.gray()
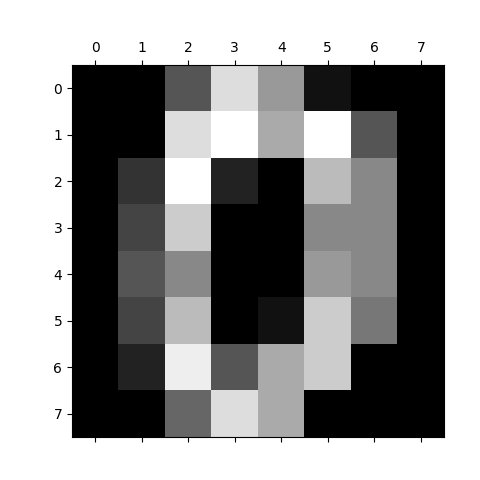
for i in range(4):
plt.matshow(digits.images[i])
plt.show()
print(digits.data[:5]) # obrazki są zapisane jako lista szarości docelowo o wymiarze 8x8
df=pd.DataFrame(digits.data)
print(df.head())
df['target']=digits.target # dodajemy kolumnę target określającą liczbę wyświetlaną
print(df.head())
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(df.drop(['target'],axis='columns'),digits.target,test_size=0.2)
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(n_estimators=20) # n_estimator określa ilość drzew decyzyjnych, domyślnie jest 10
model.fit(X_train,y_train)
print(model.score(X_test,y_test)) # sprawdzamy skuteczność modelu
y_predict=model.predict(X_test)
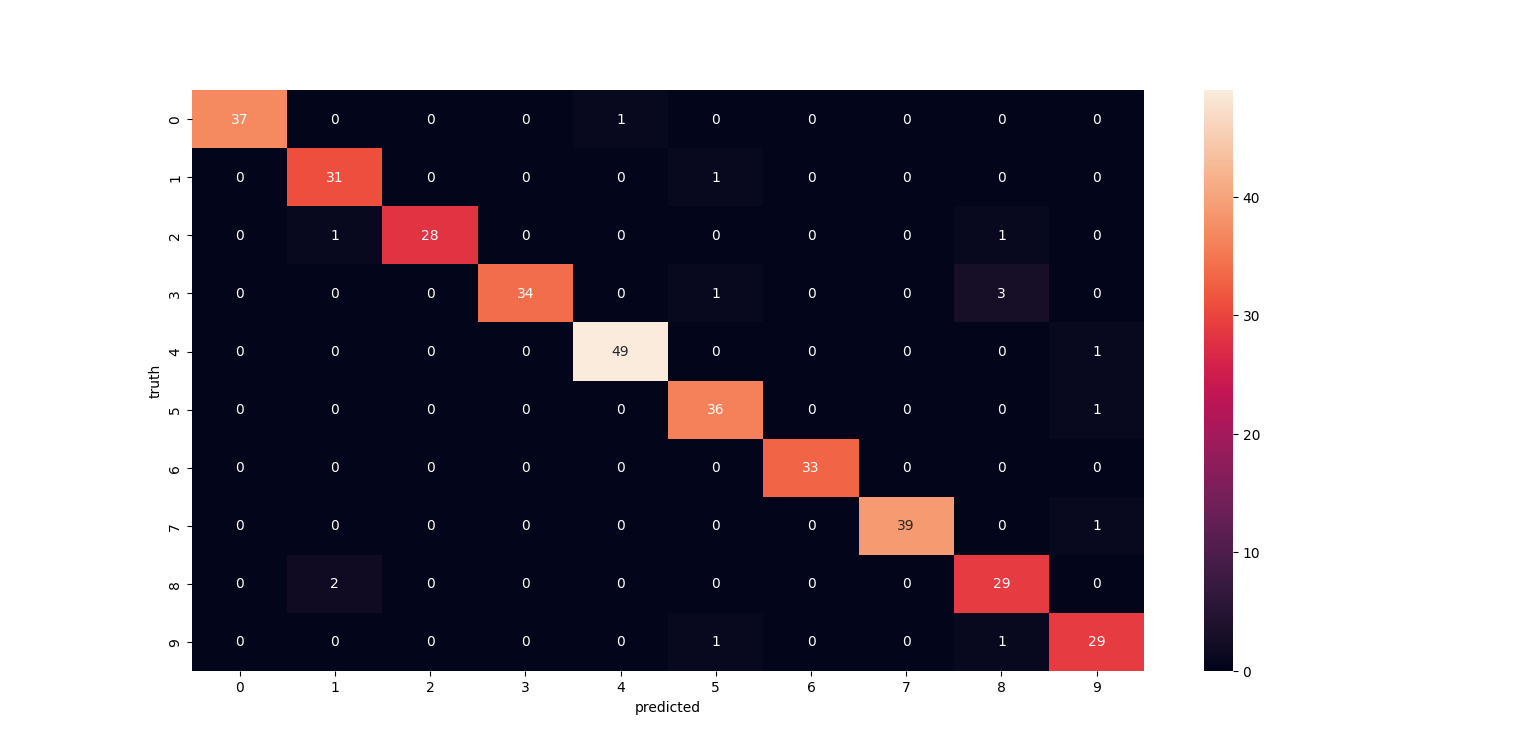
from sklearn.metrics import confusion_matrix
cm=confusion_matrix(y_test,y_predict)
print(cm)
import seaborn as sn
plt.figure(figsize=(10,7))
sn.heatmap(cm,annot=True)
plt.xlabel("predicted")
plt.ylabel("truth")
Przykładowa cyfra zapisana w macierzy 8x8.
Wykres trafnoci predykcji.