Drzewo decyzyjne
Pobierz plik z danymi "salaries.csv"
POBIERZ...
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn import tree
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
df=pd.read_csv("salaries.csv")
print(df.head())
# dzielimy dane na wejściowe i wyjściowe
inputs=df.drop('salary_more_then_100k',axis='columns')
target=df['salary_more_then_100k']
# konwertujemy stringi na liczby
le_company=LabelEncoder()
le_job=LabelEncoder()
le_degree=LabelEncoder()
inputs['comany_n']=le_company.fit_transform(inputs['company'])
inputs['job_n']=le_company.fit_transform(inputs['job'])
inputs['degree_n']=le_company.fit_transform(inputs['degree'])
print(inputs.head())
inputs_n=inputs.drop(['company','job','degree'],axis='columns')
print(inputs_n.head())
# trenujemy model drzewa
model=tree.DecisionTreeClassifier()
model.fit(inputs_n,target)
# sprawdzamy skuteczność modelu
print(model.score(inputs_n,target))
# przewidujemy przypadkowe kombinacje
print(model.predict([[2,2,1]]))
print(model.predict([[2,0,1]]))
# wizualizujemy drzewo decyzyjne
plt.figure(figsize=(20,10))
plot_tree(model,feature_names=inputs_n.columns, class_names=['<=100k','>100k'], filled=True)
plt.show()
tak wygląda drzewo decyzyjne, wygenerowane przez kod.
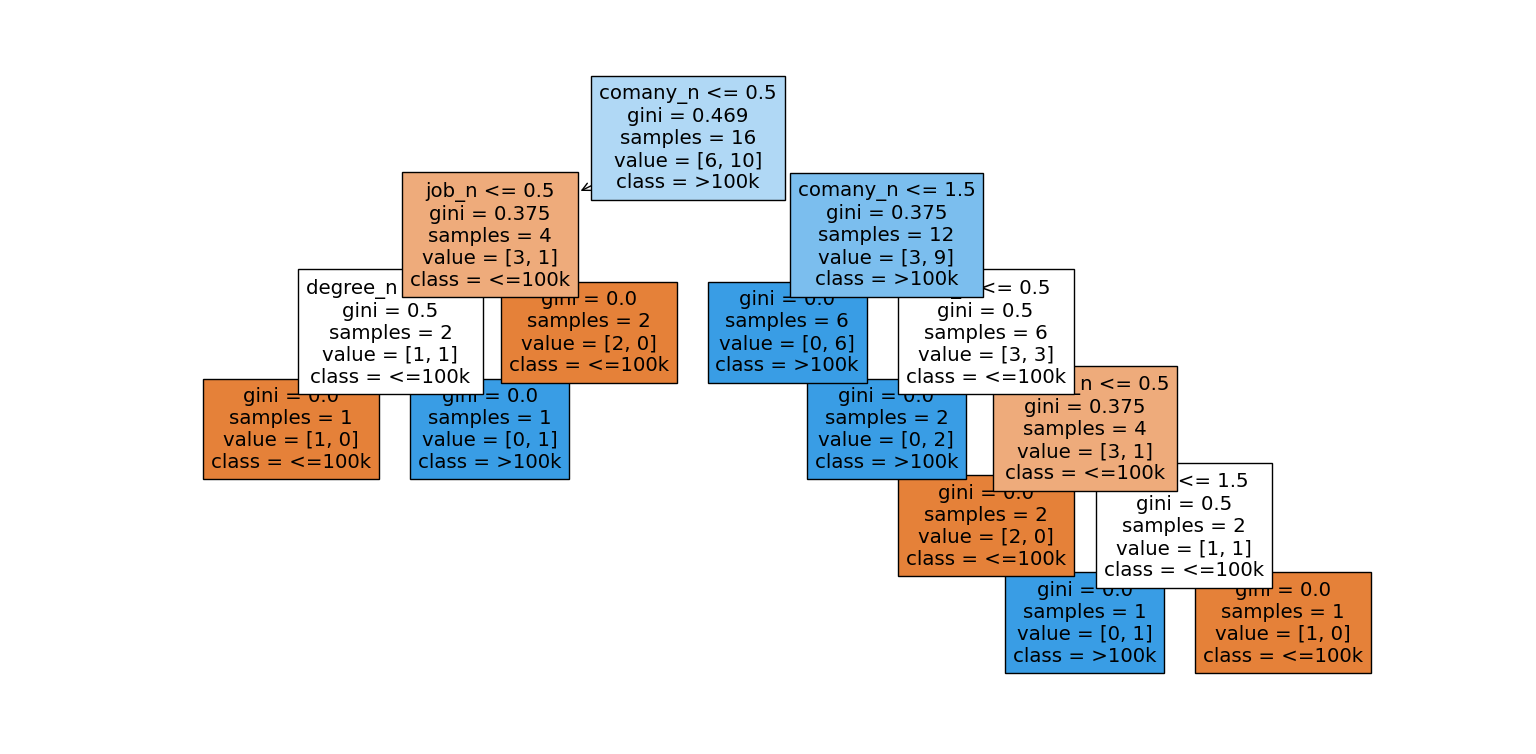 gini
gini - jest to miara niepewności węzła. Wartość 0 oznacza że dane są z tej samej klasy, wartość 0,5 oznacza że elementy są równo rozdzielone pomiędzy wszystkie klasy.
samples - liczba próbek przechodzących przez dany węzeł. Mówi ile próbek z całej populacji osiągęło ten węzeł.
value - określa ile próbek zakwalifikowano do wartości 0 i ile do wartości 1.
class - określa dominującą klasę w danym węźle.